網頁設計與制作(第2版) 任務引領下的中職計算機專業實踐探索

《網頁設計與制作 第2版》作為中等職業學校計算機及應用專業的實驗教材,是一本以“任務引領”為核心教學理念的實用型教程。它不僅緊跟網頁設計技術的最新發展,更注重培養學生的實際動手能力和項目實踐素養,為計算機專業學生步入職場奠定了堅實的基礎。
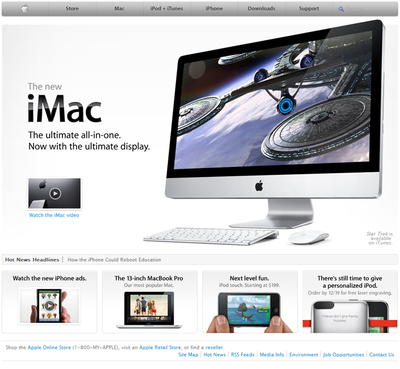
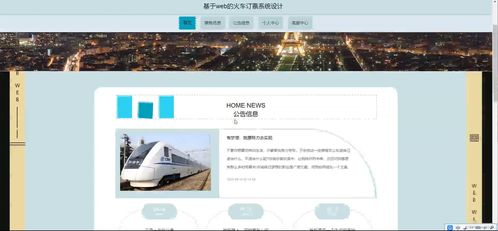
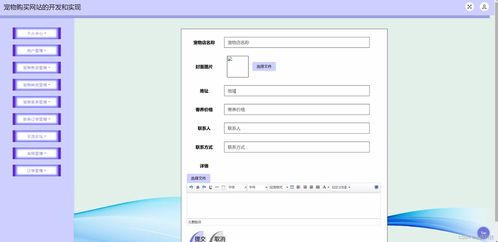
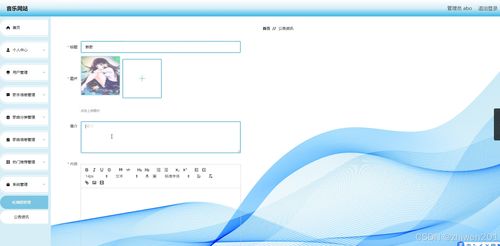
本書內容涵蓋網頁設計的基礎知識、HTML與CSS核心技術、JavaScript交互設計以及響應式布局等關鍵模塊。通過精心設計的任務案例,如“企業官網首頁制作”、“電商產品展示頁設計”等,教材引導學生從零開始,逐步掌握網頁結構搭建、樣式美化、功能實現的全流程。每個任務都配有清晰的步驟說明、代碼示例和效果演示,確保學生能夠“學中做、做中學”,有效化解理論知識的抽象性。
作為實驗教材,本書特別強調實踐環節的設計。每個章節后附有拓展練習和綜合項目,鼓勵學生舉一反三,自主創新。例如,在學習了導航欄制作后,學生需獨立設計一個具有下拉菜單功能的導航系統;在掌握了響應式布局原理后,需完成一個適配手機、平板和電腦的多端網頁。這種以任務驅動學習的方式,極大地激發了學生的學習興趣和解決問題的能力。
教材還融入了網頁設計的美學原則與用戶體驗(UX)基礎概念,幫助學生理解設計不僅僅是技術實現,更是藝術與功能的結合。通過分析優秀網頁案例,學生可以培養審美觀和用戶思維,從而制作出既美觀又實用的網頁作品。
《網頁設計與制作 第2版》以其任務引領的特色、系統化的內容編排和強調實踐的教學設計,成為了中等職業學校計算機專業網頁設計課程的理想教材。它不僅傳授技術知識,更致力于培養適應行業需求的復合型技能人才,為學生未來的職業發展打開了一扇通往數字世界的大門。
如若轉載,請注明出處:http://www.fgetchr.cn/product/58.html
更新時間:2026-05-30 16:12:22